If we want to use text in Machine Learning algorithms, we’ll have to convert then to a numerical representation. It should be no surprise that computers are very well at handling numbers.
We convert text to a numerical representation called a feature vector. A feature vector can be as simple as a list of numbers.
The bag-of-words model is one of the feature extraction algorithms for text.
Related course: Complete Machine Learning Course with Python
Feature extraction from text
The bag of words model ignores grammar and order of words.
We start with two documents (the corpus):
'All my cats in a row',
'When my cat sits down, she looks like a Furby toy!',
A list in then created based on the two strings above:
{'all': 0, 'cat': 1, 'cats': 2, 'down': 3, 'furby': 4, 'in': 5, 'like': 6, 'looks': 7, 'my': 8, 'row': 9, 'she': 10, 'sits': 11, 'toy': 12, 'when': 13 }
The list contains 14 unique words: the vocabulary. That’s why every document is represented by a feature vector of 14 elements. The number of elements is called the dimension.
Then we can express the texts as numeric vectors:
[[1 0 1 0 0 1 0 0 1 1 0 0 0 0]
[0 1 0 1 1 0 1 1 1 0 1 1 1 1]]
Lets take a closer look:
'All my cats in a row' = [1 0 1 0 0 1 0 0 1 1 0 0 0 0]
If we follow the order of the vocabulary:
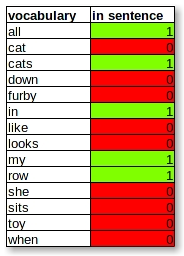
we’ll get a vector, the bag of words representation.
Bag of words code
We’ll define a collection of strings called a corpus. Then we’ll use the CountVectorizer to create vectors from the corpus.
# Feature extraction from text |
If you are new to Machine Learning, I highly recommend this book