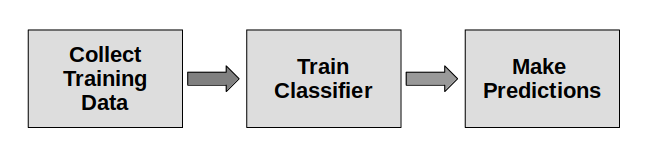
Training and test data are common for supervised learning algorithms. Given a dataset, its split into training set and test set.
In Machine Learning, this applies to supervised learning algorithms.
Related course: Complete Machine Learning Course with Python
Training and test data
In the real world we have all kinds of data like financial data or customer data.
An algorithm should make new predictions based on new data.
You can simulate this by splitting the dataset in training and test data.
Code example
The module sklearn comes with some datasets. One of these dataset is the iris dataset.
We load this data using the method load_iris() and then get the data and labels (class of flower).
Then the data is split randomly using the method train_test_split.
As parameters we specify the train_size and test_size, both at 50%.
|