Do you have observed data?
You can cluster it automatically with the kmeans algorithm.
In the kmeans algorithm, k is the number of clusters.
Clustering is an _unsupervised machine learning task. _ Everything is automatic.
Related course: Complete Machine Learning Course with Python
kmeans data
We always start with data. This is our observed data, simply a list of values.
We plot all of the observed data in a scatter plot.
# clustering dataset |
Result: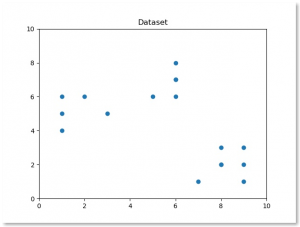
kmeans clustering example
We will cluster the observations automatically.
K can be determined using the elbow method, but in this example we’ll set K ourselves.
Note: K is always a positive integer. We cannot have -1 clusters (k).
The k-means clustering algorithms goal is to partition observations into k clusters.
Each observation belong to the cluster with the nearest mean.
# clustering dataset |
Result: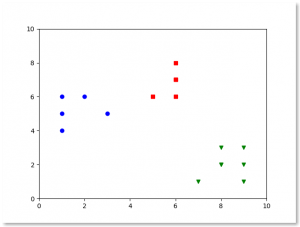
If you see the above result, Kmeans has clustered the observations automatically.