Machine Learning is an advanced technique where algorithms learn from data. The primary objectives of these algorithms can be categorized under certain tasks. Among the most popular Machine Learning tasks are classification, regression, and clustering.
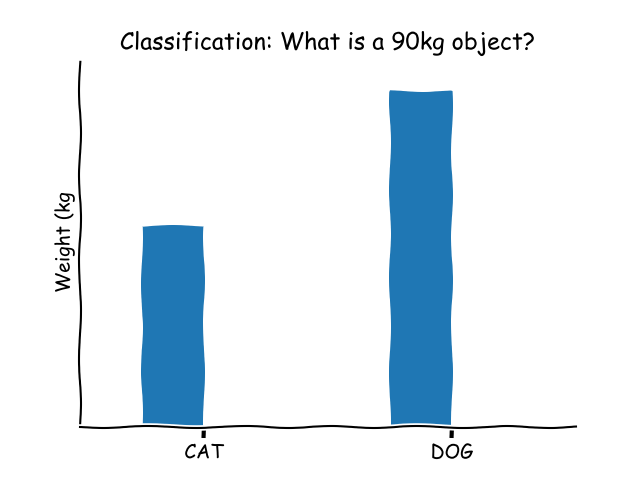
Classification
When you have data, such as images of animals, it’s possible to categorize or classify them. For instance, identifying one image as a cat and another as a dog.
Using specific Machine Learning algorithms designed for classification, computers can execute this task. It’s especially practical in real-world applications such as voice recognition or object detection.
Classification falls under supervised learning. In this approach, you train the algorithm using a dataset where you already know the output, guiding the algorithm to learn patterns.
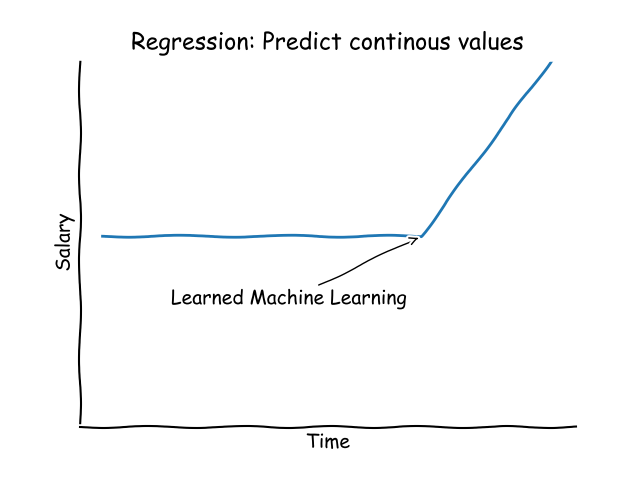
Regression
Predictive tasks often revolve around estimating or forecasting certain values. Questions like “What will be the sales figure next month?” or “How much salary should be offered for this position?” are tackled using regression.
The primary objective in regression is to estimate or predict a continuous variable. Just like classification, regression is a supervised learning task where the algorithm is trained using data with known outputs.
Clustering
Clustering involves working with data points, which could be measurements such as length or width. These measurements can be represented visually, with each data entry plotted as a point.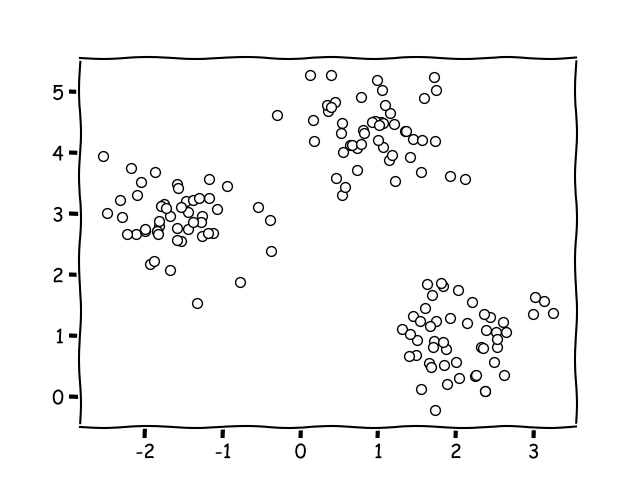
The main goal in clustering is to group or segment these data points into clusters based on similarities or differences in their features. These assignments are done based on specific algorithms.
As clustering is unsupervised, the algorithm determines the clusters automatically without prior training.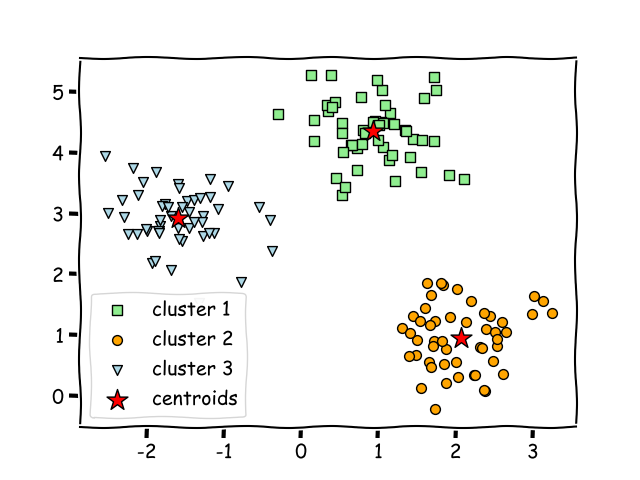
A practical application of clustering is document organization. Imagine having several files on your computer. With clustering, the computer can autonomously categorize them based on content similarities.