With the advent of machine learning and artificial intelligence, machines are getting more and more advanced and their abilities are frequently pushed to the limit.
Nowhere is this more tested than in unsupervised learning, which is a format of learning that a machine uses without any form of training data or guidance.
This form of learning as been more closely associated with true artificial intelligence. Whereas supervised learning may be more popular and common, I will highlight benefits and categories of unsupervised learning in this article.
Related course: Complete Machine Learning Course with Python
Why Unsupervised Learning?
The number one advantage of unsupervised learning is the ability for a machine to tackle problems that humans might find insurmountable either due to a limited capacity or a bias.
Unsupervised learning is ideal for exploring raw and unknown data. It works for a data scientist that does not necessarily know what he or she is looking for.
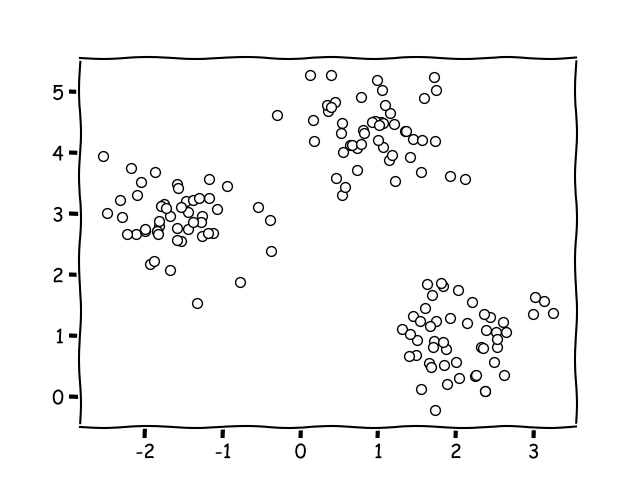
When presented with data, an unsupervised machine will search for similarities between the data namely images and separate them into individual groups, attaching its own labels onto each group.
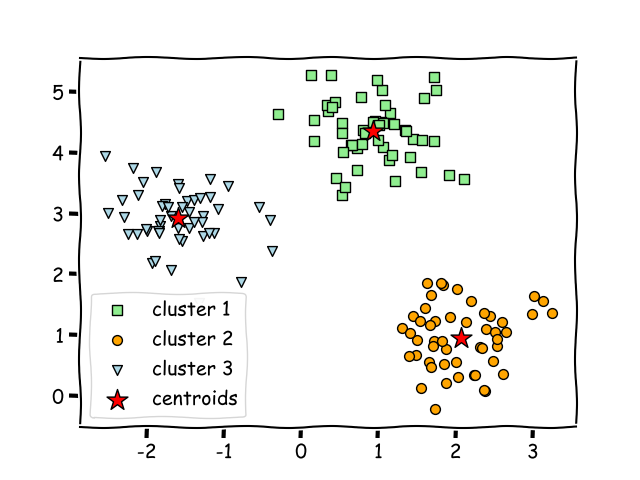
This kind of algorithmic behavior is very useful when it comes to segmenting customers as it can easily separate data into groups without any form of bias that might hinder a human due to pre-existing knowledge about the nature of the data on the customers.
Compared to human intelligence
Additionally, unsupervised learning is closer to human cognitive functions as just like a human brain, it deduces patterns from around the world and slowly learns more about the world over time.
A good example would be a child that is been introduced to the world for the first time. Let’s imagine it sees a two-legged creature and hears someone call that creature a chicken, the next couple of two legged creatures it sees whether they be ducks, turkeys or geese would register as chickens to the child.
However, over a period of time, after the child consumes more information on other two-legged creatures like ducks, turkeys or geese, it slowly begins to discern which two-legged creature is which without any external supervision.
Given data x, the unsupervised learning algorithm kmeans trains itself.
kmeans = KMeans(n_clusters=2, random_state=0).fit(X) |
This is an example of how unsupervised learning works, furthermore it can be placed under four categories which are clustering, descending dimensions, association and recommendation systems, and reinforcement learning.
Clustering
Clustering is used for significantly reducing large data into simplified forms of information that can be easily digested.
| Length | Breath | Height | Class |
|---|---|---|---|
| 100 | 100 | 20 | Football Field |
| 5 | 5 | 2 | Room |
| 9 | 6 | 2 | Room |
Descending dimensions are useful in reducing the time taken for a computer to process information.
By merging certain fundamental dimensions for faster results like in a three-dimension system of length, breath and height, the computer can make it a two-dimension system by merging the length and breath into area.
| Area | Height | Class |
|---|---|---|
| 10000 | 20 | Football Field |
| 25 | 2 | Room |
| 54 | 2 | Room |
Recommender systems
Association and recommendation systems operate by collating historical data on a person and suggesting recommendations based on their past viewership and even social media relationships.
This is prevalent in Netflix recommendation tabs, Facebook friend suggestions, Youtube Videos and many more.
Reinforcement learning
Reinforcement learning is a way of making your computer learn by experience through rigorous tactics of trial and error.
All these points highlight the importance of unsupervised learning and showcases their various applications.